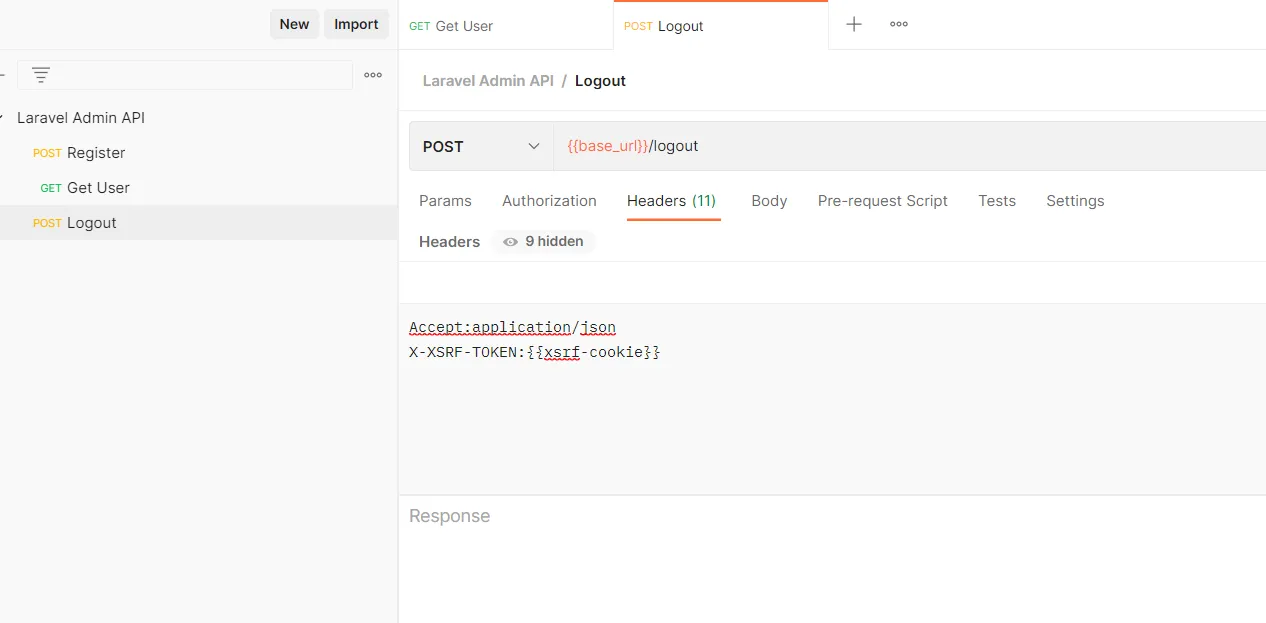
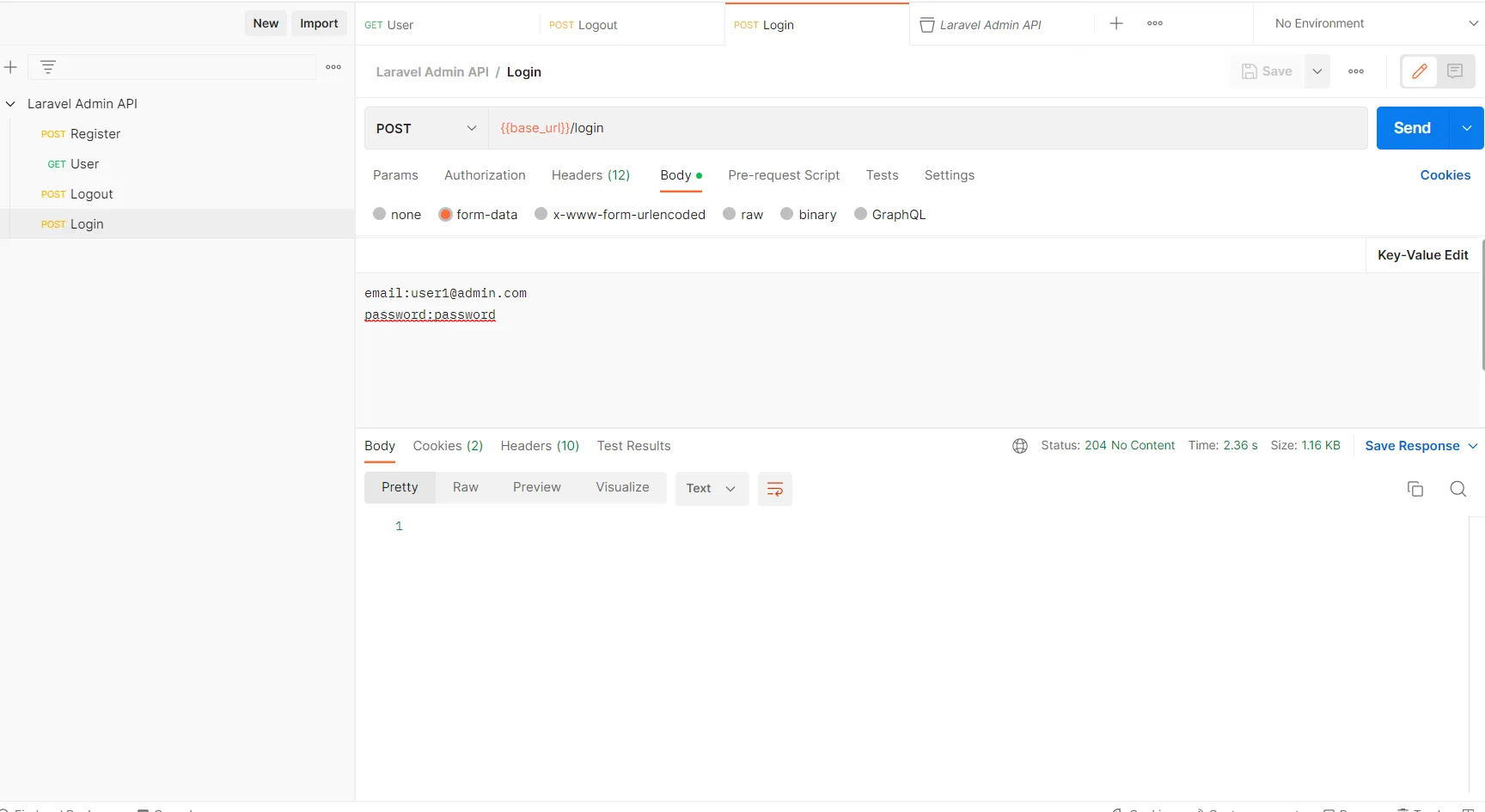
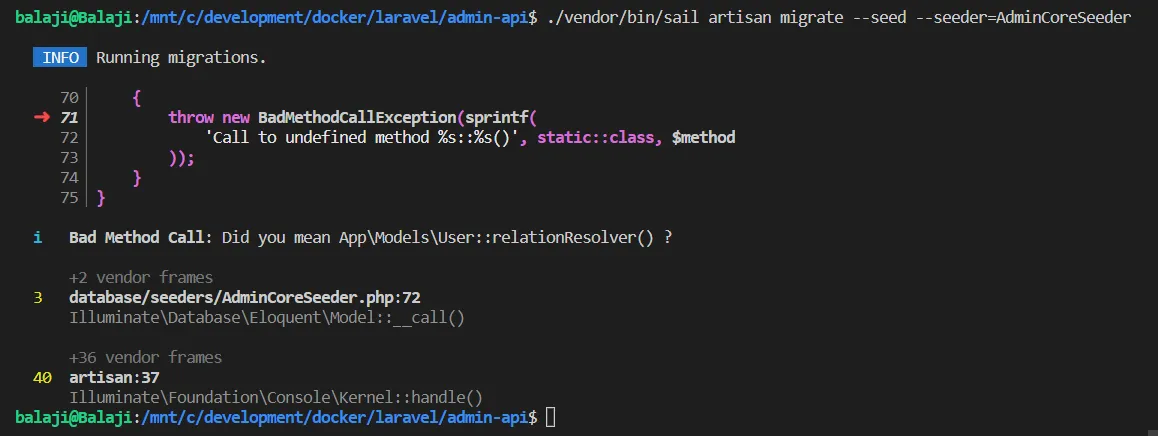
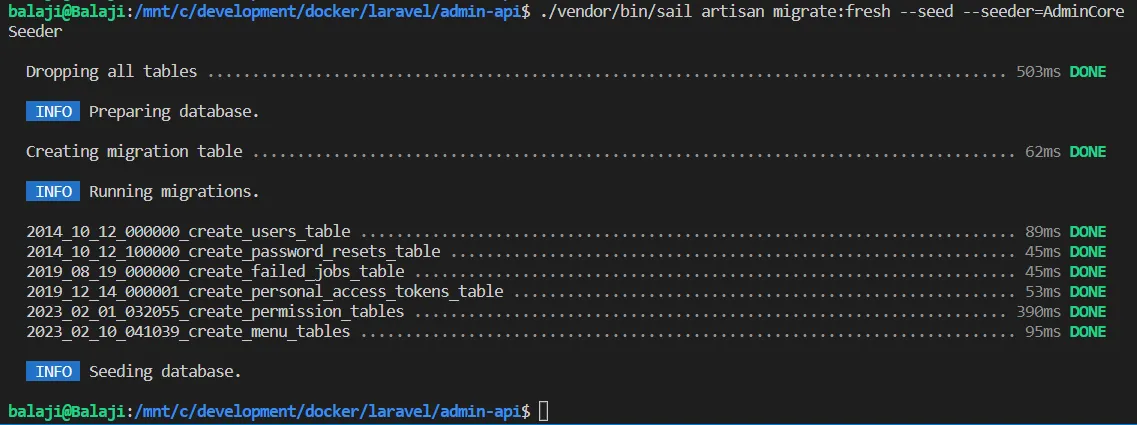
There has never been a better time to start your data science homelab for analyzing data useful to you, storing important information, or developing your own tech skills.
Will Keefe Published in Towards Data Science
There’s an expression I’ve read on Reddit a few times now in varying tech-focused subreddits that is along the lines of “Paying for cloud services is just renting someone else’s computer.” While I do think cloud computing and storage can be extremely useful, this article will focus on some of the reasons why I’ve moved my analyses, data stores, and tools away from the online providers, and into my home office. A link to the tools and hardware I used to do this is available as well.
Introduction
The best way to start explaining the method to my madness is by sharing a business problem I ran into. While I’m a fairly traditional investor with a low-risk tolerance, there is a small hope inside of me that maybe, just maybe, I can be one of the <1% to beat the S&P 500. Note I used the word “hope”, and us such, do not put too much on the line in this hope. A few times a year I’ll give my Robinhood account $100 and treat it with as much regard as I treat a lottery ticket — hoping to break it big. I will put the adults in the room at ease though by sharing that this account is separate from my larger accounts that are mostly based on index funds with regular modest returns with a few value stocks I sell covered calls on a rolling basis with. My Robinhood account however is borderline degenerate gambling, and anything goes. I have a few rules for myself though:
- I never take out any margin.
- I never sell uncovered, only buy to open.
- I don’t throw money at chasing losing trades.
You may wonder where I’m going with this, and I’ll pull back from my tangent by sharing that my “lottery tickets” that have, alas, not earned me a Jeff-Bezos-worthy yacht yet, but have taught me a good bit about risk and loss. These lessons have also inspired the data enthusiast inside of me to try to improve the way I quantify risk and attempt to anticipate market trends and events. Even models directionally correct in the short term can provide tremendous value to investors — retail and hedge alike.
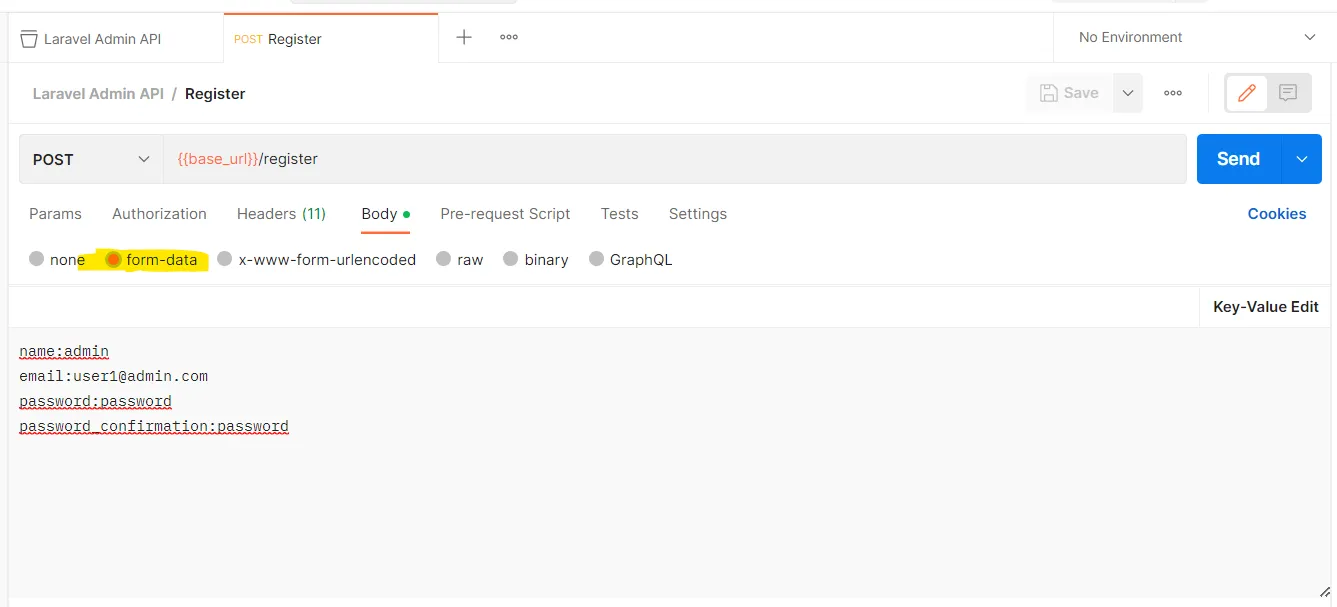
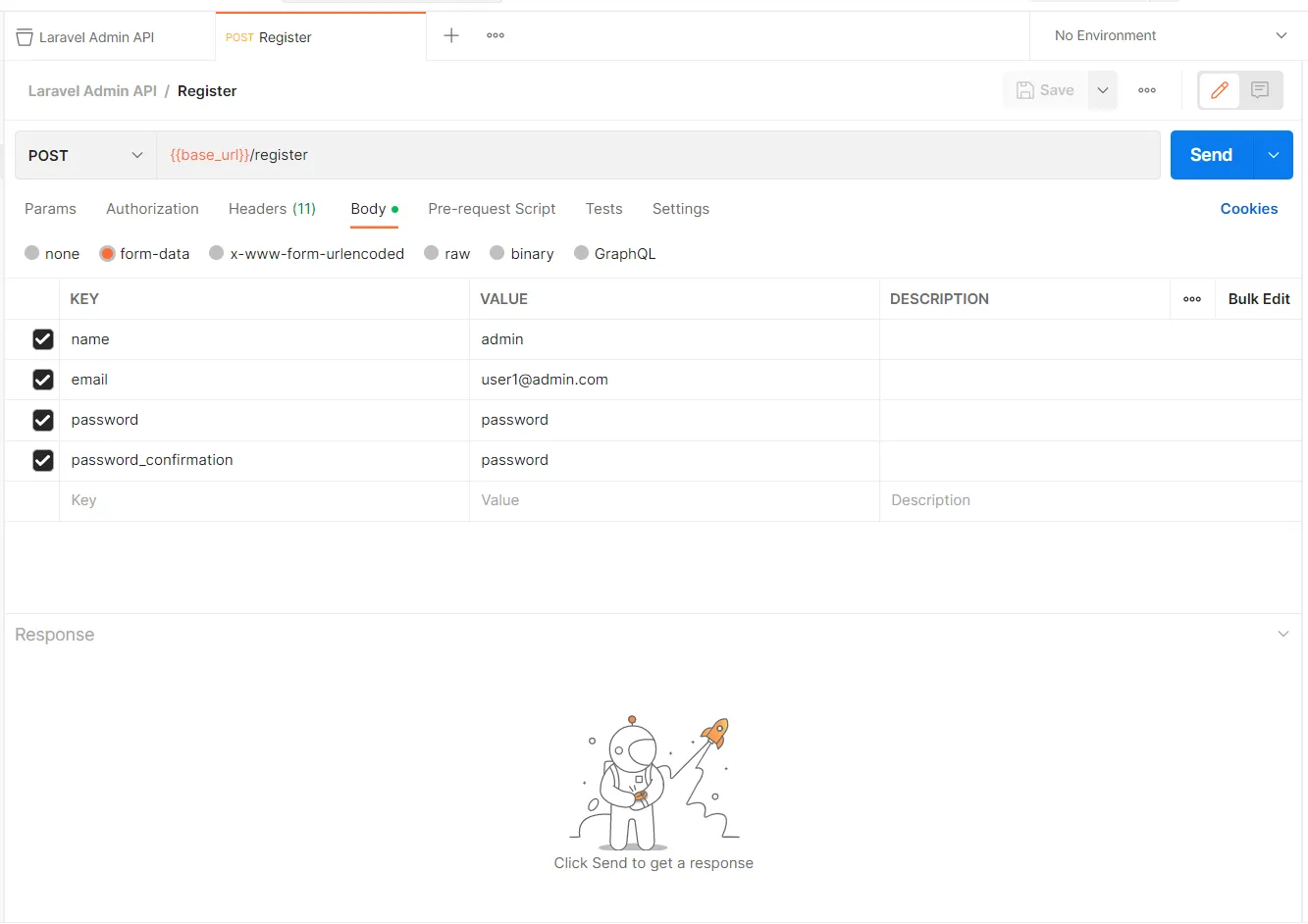
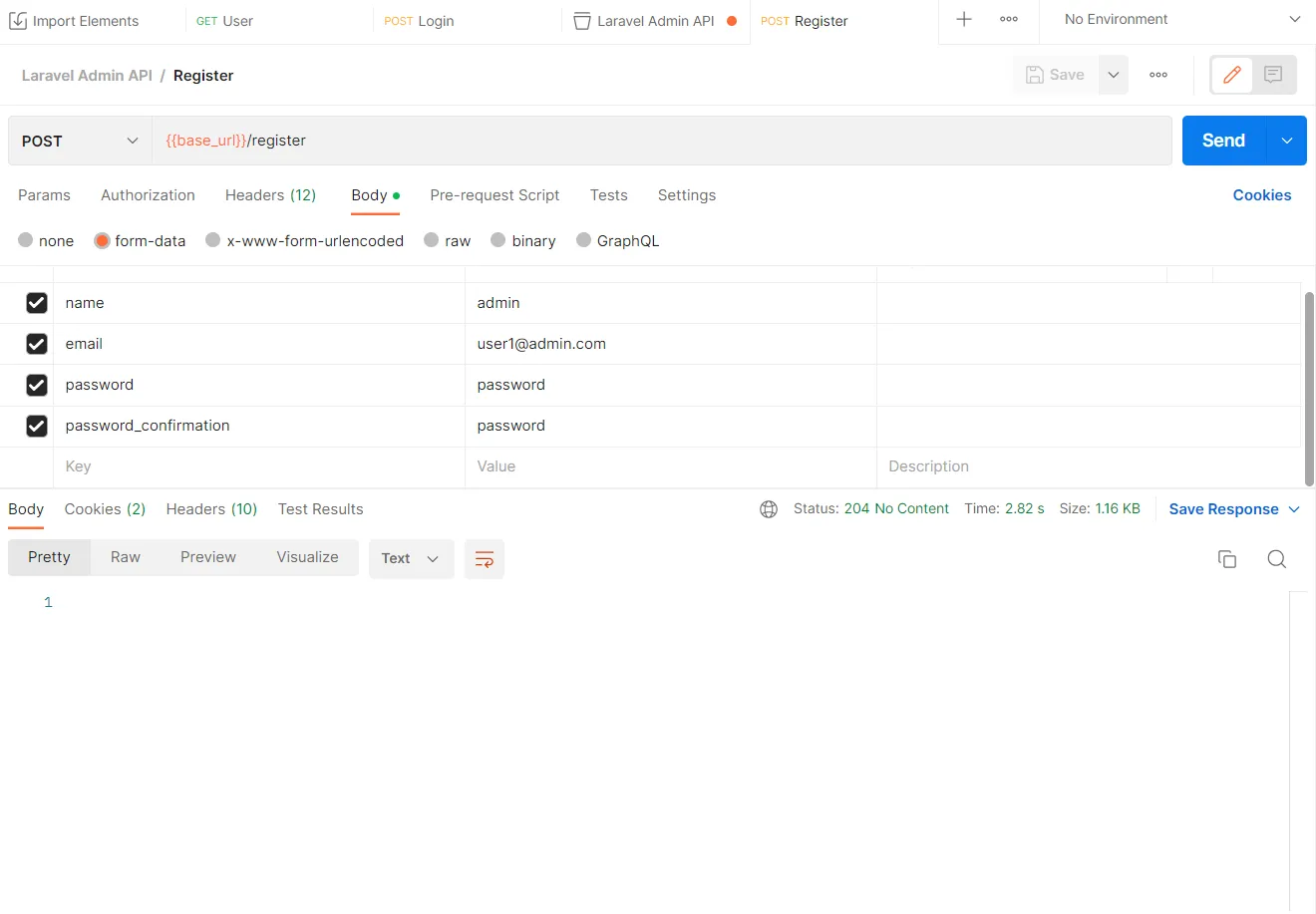
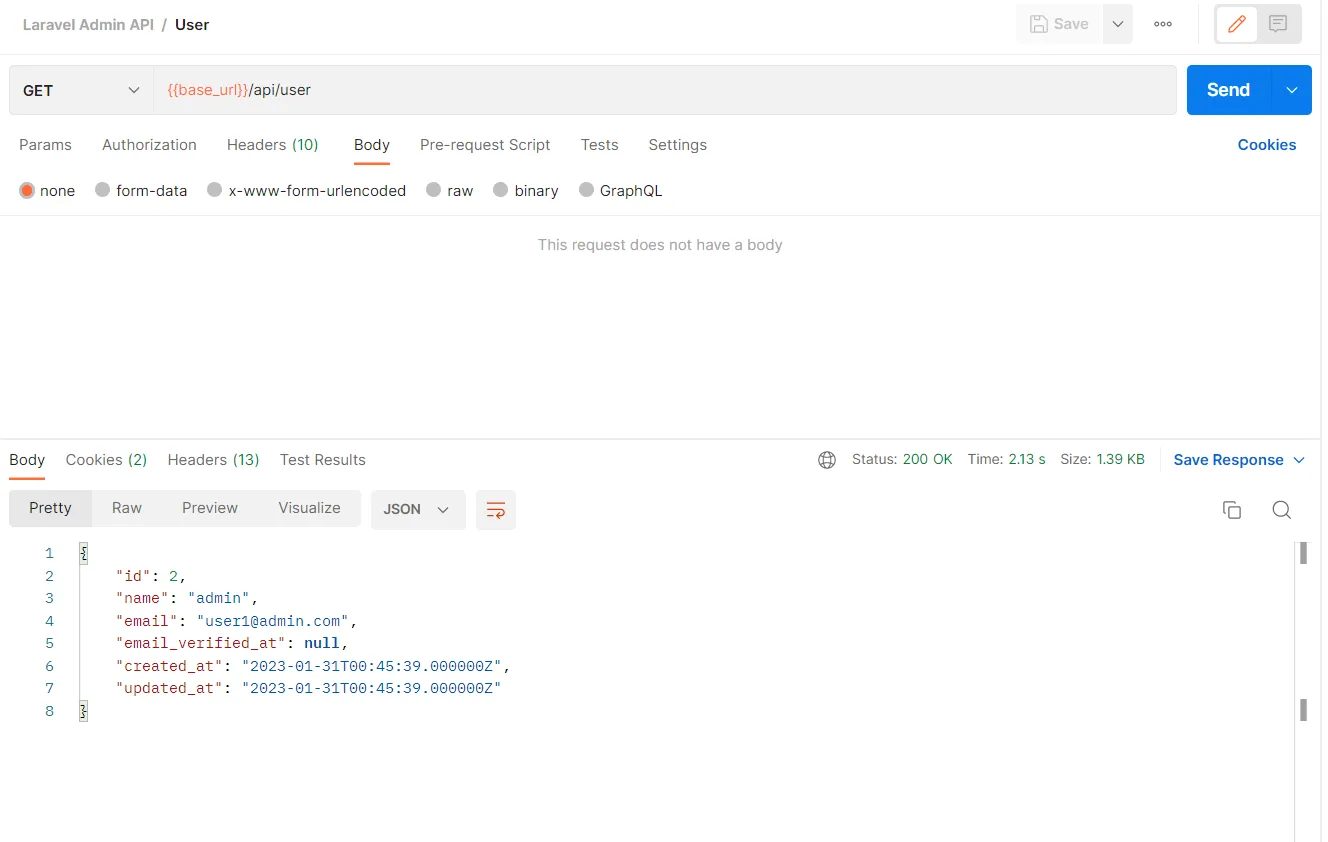
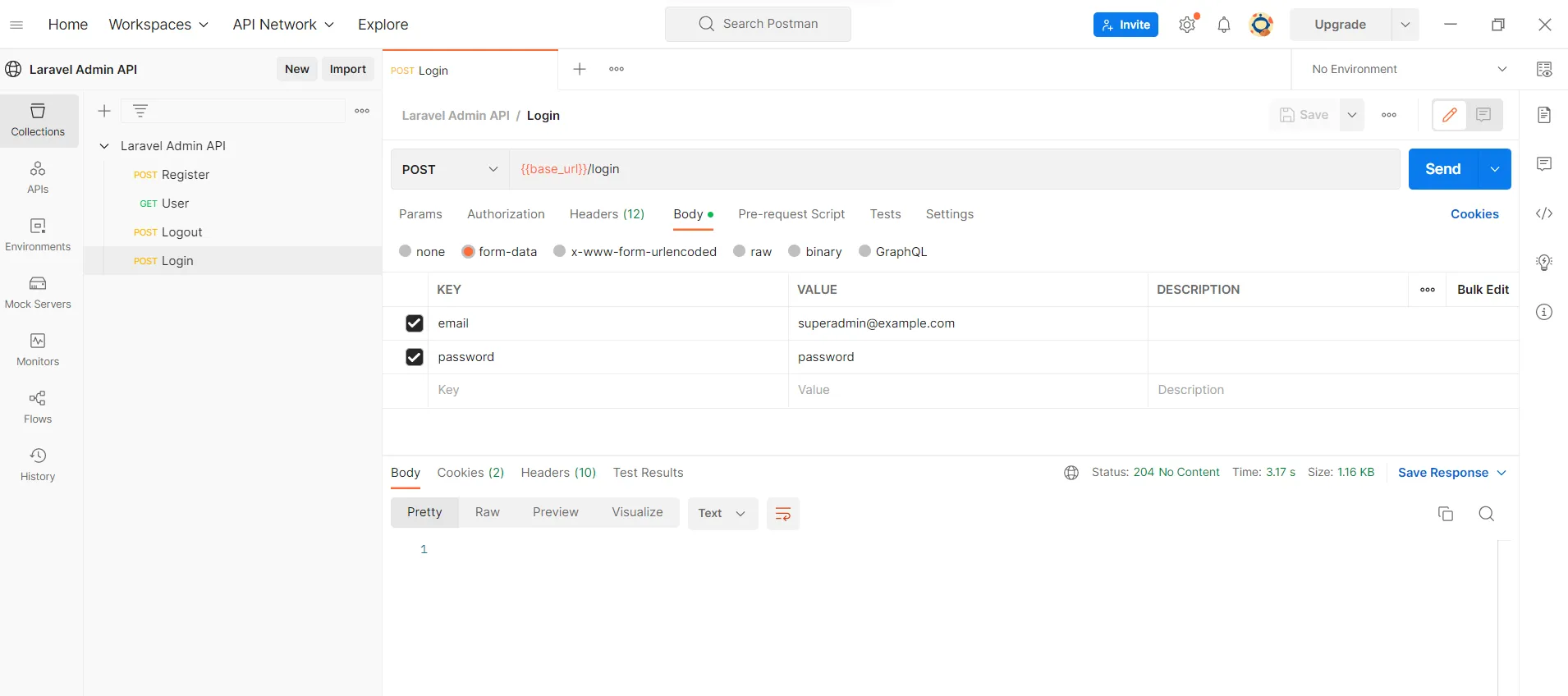
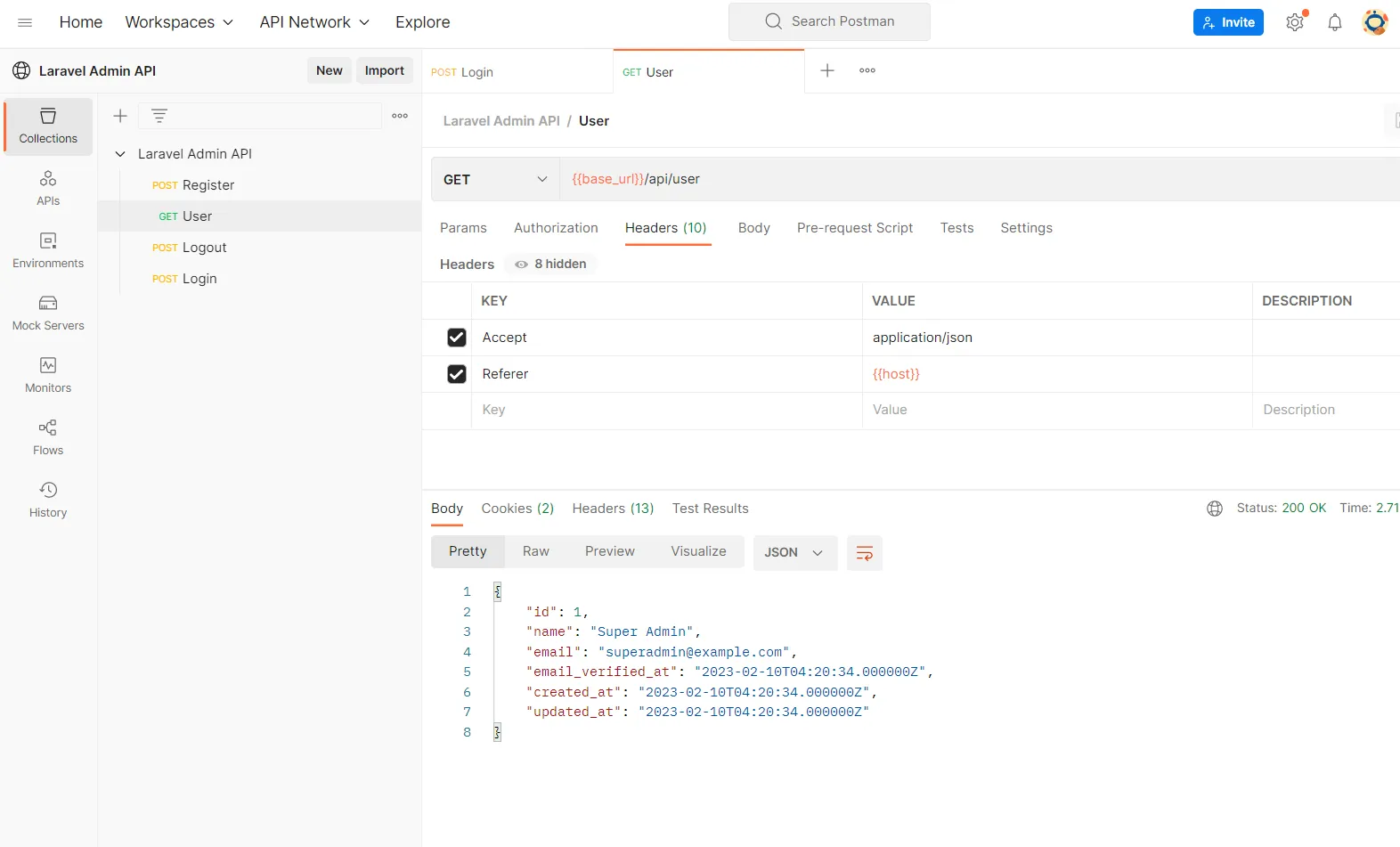
The first step I saw toward improving my decision-making was to have data available to make data-driven decisions. Removing emotion from investing is a well-known success tip. While historical data is widely available for stocks and ETFs and is open-sourced through resources such as yfinance (an example of mine is below), derivative historical datasets are much more expensive and difficult to come by. Some initial glances at the APIs available provided hints that regular, routine access to data to backtest strategies for my portfolio could cost me hundreds of dollars annually, and possibly even monthly depending on the granularity I was seeking.
I decided I’d rather invest in myself in this process, and spend $100’s of dollars on my own terms instead. *audience groans*
Building on the Cloud
My first thoughts on data scraping and warehousing led me to the same tools I use daily in my work. I created a personal AWS account, and wrote Python scripts to deploy on Lambda to scrape free, live option datasets at predetermined intervals and write the data on my behalf. This was a fully automated system, and near-infinitely scalable because a different scraper would be dynamically spun up for every ticker in my portfolio. Writing the data was more challenging, and I was nestled between two routes. I could either write the data to S3, crawl it with Glue, and analyze it with serverless querying in Athena, or I could use a relational database service and directly write my data from Lambda to the RDS.
A quick breakdown of AWS tools mentioned:
Lambda is serverless computing allowing users to execute scripts without much overhead and with a very generous free tier.
S3, aka simple storage service, is an object storage system with a sizable free tier and extremely cost-effective storage at $0.02 per GB per month.
Glue is an AWS data prep, integration, and ETL tool with web crawlers available for reading and interpreting tabular data.
Athena is a serverless query architecture.
I ended up leaning toward RDS just to have the data easily queryable and monitorable, if for no other reason. They also had a free tier available of 750 hours free as well as 20 GB of storage, giving me a nice sandbox to get my hands dirty in.
Little did I realize, however, how large stock options data is. I began to write about 100 MB of data per ticker per month at 15-minute intervals, which may not sound like much, but considering I have a portfolio of 20 tickers, before the end of the year I would have used all of the entirety of the free tier. On top of that, the small compute capacity within the free tier was quickly eaten up, and my server ate through all 750 hours before I knew it (considering I wanted to track options trades for roughly 8 hours a day, 5 days a week). I also frequently would read and analyze data after work at my day job, which led to greater usage as well. After about two months I finished the free tier allotment and received my first AWS bill: about $60 a month. Keep in mind, once the free tier ends, you’re paying for every server hour of processing, an amount per GB out of the AWS ecosystem to my local dev machine, and a storage cost in GB/month. I anticipated within a month or two my costs of ownership could increase by at least 50% if not more, and continue so on.
Leaving the Cloud
At this point, I realized how I’d rather be taking that $60 a month I am spending renting equipment from Amazon, and spend it on electric bills and throwing what is left over into my Robinhood account, back where we started. As much as I love using AWS tools, when my employer isn’t footing the bill (and to my coworkers reading this, I promise I’m frugal at work too), I really don’t have much interest in investing in them. AWS just is not priced at the point for hobbyists. They give plenty of great free resources to learn to noobies, and great bang for your buck professionally, but not at this current in-between level.
I had an old Lenovo Y50–70 laptop from prior to college with a broken screen that I thought I’d repurpose as a home web scraping bot and SQL server. While they still can fetch a decent price new or certified refurbished (likely due to the i7 processor and dedicated graphics card), my broken screen pretty much totaled the value of the computer, and so hooking it up as a server breathed fresh life into it, and about three years of dust out of it. I set it up in the corner of my living room on top of a speaker (next to a gnome) and across from my PlayStation and set it to “always on” to fulfill its new purpose. My girlfriend even said the obnoxious red backlight of the computer keys even “pulled the room together” for what it’s worth.

Conveniently my 65″ Call-of-Duty-playable-certified TV was within HDMI cable distance to the laptop to actually see the code I was writing too.
I migrated my server from the cloud to my janky laptop and was off to the races! I could now perform all of the analysis I wanted at just the cost of electricity, or around $0.14/kWh, or around $0.20–0.30 a day. For another month or two, I tinkered and tooled around locally. Typically this would look like a few hours a week after work of opening up my MacBook, playing around with ML models with data from my gnome-speaker-server, visualizing data on local Plotly dashboards, and then directing my Robinhood investments.
I experienced some limited success. I’ll save the details for another Medium post once I have more data and performance metrics to share, but I decided I wanted to expand from a broken laptop to my own micro cloud. This time, not rented, but owned.
Building the Home Lab
“Home Lab” is a name that sounds really complicated and cool *pushes up glasses*, but is actually relatively straightforward when deconstructed. Basically, there were a few challenges I was looking to address with my broken laptop setup that provided motivation, as well as new goals and nice-to-haves that provided inspiration.
Broken laptop problems:
The hard drive was old, at least 5 or 6 years old, which posed a risk to potential future data loss. It also slowed down significantly under duress with larger queries, a noted problem with the model.
Having to use my TV and Bluetooth keyboard to use my laptop with Windows 10 Home installed was very inconvenient, and not ergonomically friendly.
The laptop was not upgradeable in the event I wanted to add more RAM beyond what I had already installed.
The technology was limited in parallelizing tasks.
The laptop alone was not strong enough to host my SQL server as well as dashboards and crunching numbers for my ML models. Nor would I feel comfortable sharing the resources on the same computer, shooting the other services in the feet.
A system I would put into place had to solve each of these problems, but there were also new features I’d like to achieve too.
Planned New Features:
A new home office setup to make working from home from time to time more comfortable.
Ethernet wiring throughout my entire apartment (if I’m paying for the whole gigabit, I’m going to use the whole gigabit AT&T).
Distributed computing* with microservers where appropriate.
Servers would be capable of being upgraded and swapped out.
Varying programs and software deployable to achieve different subgoals independently and without impeding current or parallel programs.
*Distributed computing with the computers I chose is a debated topic that will be explained later in the article.
I spent a good amount of time conducting research on appropriate hardware configurations. One of my favorite resources I read was “Project TinyMiniMicro”, which compared the Lenovo ThinkCentre Tiny platform, the HP ProDesk/EliteDesk Mini Platform, and the Dell OptiPlex Micro platform. I too have used single-board computers before like the authors of Project TMM, and have two Raspberry Pis and an Odroid XU4.
What I liked about my Pis:
They were small, ate little power, and the new models have 8GB of RAM.
What I liked about my Odroid XU4:
It is small, has 8 cores, and is a great emulation platform.
While I’m sure my SBCs will still find a home in my homelab, remember, I need equipment that handles the services I want to host. I also ended up purchasing probably the most expensive Amazon order of my entire life and completely redid my entire office. My shopping cart included:
- Multiple Cat6 Ethernet Cables
- RJ45 Crimp Tool
- Zip ties
- 2 EliteDesk 800 G1 i5 Minis (but was sent G2 #Win)
- 1 EliteDesk 800 G4 i7 Mini (and sent an even better i7 processor #Win)
- 2 ProDesk 600 G3 i5 Minis (and send sent a slightly worse i5 #Karma)
- Extra RAM
- Multiple SSDs
- A new office desk to replace my credenza/runner
- New office lighting
- Hard drive cloning equipment
- Two 8-Port Network Switches
- An Uninterruptible Power Supply
- A Printer
- A Mechanical Keyboard (Related, I also have five keyboard and mice combos from the computers if anyone wants one)
- Two new monitors
If you’d like to see my entire parts list with links to each item to check it out or two make a purchase for yourself, feel free to head over to my website for a complete list.
Once my Christmas-in-the-Summer arrived with a whole slew of boxes on my doorstep, the real fun could begin. The first step was finishing wiring my ethernet throughout my home. The installers had not connected any ethernet cables to the cable box by default, so I had to cut the ends and install the jacks myself. Fortunately, the AWESOME toolkit I purchased (link on my site) included the crimp tool, the RJ45 ends, and testing equipment to ensure I wired the ends right and to identify which port around my apartment correlated to which wire. Of course, with my luck, the very last of 8 wires ended up being the one I needed for my office, but the future tenants of my place will benefit from my good deed for the day I guess. The entire process took around 2–3 hours of wiring the gigabit connections but fortunately, my girlfriend enjoyed helping and a glass of wine made it go by faster.
Following wired networking, I began to set up my office by building the furniture, installing the lighting, and unpacking the hardware. My desk setup turned out pretty clean, and I’m happy with how my office now looks.


As for my hardware setup, each of the computers I purchased had 16GB of RAM I upgraded to 32 as well as Solid State Drives (a few I upgraded). Since every device is running Windows 10 Pro, I am able to remote login in my network as well and I set up some of my service already. Networking the devices was quite fun as well, although I think my cable management leaves a little room for improvement.




Now per the asterisk I had in the beginning, why did I spend around a year’s worth of AWS costs on five computers with like 22 cores total rather than just buy/build a tricked-out modern PC? Well, there are a few reasons, and I’m sure this may be divisive with some of the other tech geeks in the room.
- Scalability — I can easily add another node to my cluster here or remove one for maintenance/upgrades.
- Cost — It is easy and cheap to upgrade and provide maintenance. Additionally, at around 35W max for most units, the cost of running my servers is very affordable.
- Redundancy — If one node goes down (ie, a CPU dies), I have correcting scripts to balance my distributed workloads.
- Education — I am learning a significant amount that furthers my professional skills and experience, and education is ✨invaluable✨.
- It looks cool. Point number 5 here should be enough justification alone.
Speaking of education though, here are some of the things I learned and implemented in my cluster:
- When cloning drives from smaller to larger, you will need to extend the new drive’s volumes which frequently requires 3rd party software to do easily (such as Paragon).
- You need to manually assign static IPs to get reliable results when remoting between desktops.
- When migrating SQL servers, restoring from a backup is easier than querying between two different servers.
I’m sure there will be many more lessons I will learn along the way…
Below is an approximate diagram of my home network now. Not pictured are my wifi devices such as my MacBook and phone, but they jump between the two routers pictured. Eventually, I will also be adding my single-board computers and possibly one more PC to the cluster. Oh yeah, and my old broken-screen-laptop? Nobody wanted to buy it on Facebook Marketplace for even $50 so I installed Windows 10 Pro on it for remote access and added it to the cluster too for good measure, and that actually could be a good thing because I can use its GPU to assist in building Tensorflow models (and play a few turn-based games as well).
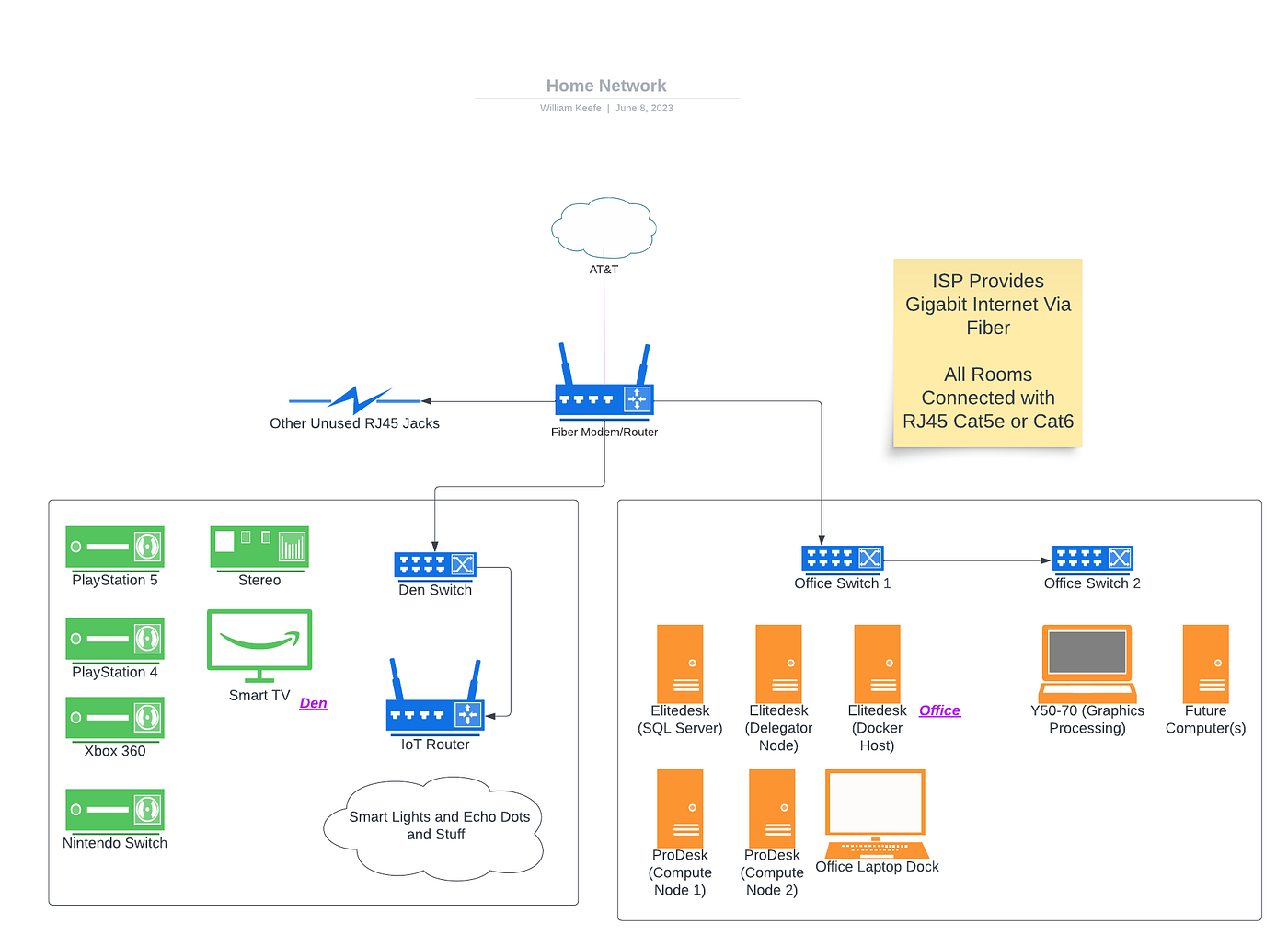
Speaking of Tensorflow, here are some of the services and functions I will be implementing in my new home lab:
- The SQL server (currently hosting my financial datasets, as well as new datasets I am web scraping and will later write about including my alma mater’s finances and the city I am living in’s public safety datasets)
- Docker (for hosting apps/containers I will be building as well as a Minecraft server, because, why not)
- Jenkins CI/CD system to build, train, and deploy Machine Learning models on my datasets
- Git Repo for my personal codebase
- Network Attached Storage supporting my many photos from my photography hobby, documents, and any other data-hoarding activities
- And other TBD projects/services
Closing Thoughts:
Was it worth it? Well, there is an element of “only time will tell”. Once my credit card cools off from my Amazon fulfillment purchases I’m sure it will enjoy the reprieve from AWS pricing as well. I am also looking forward to being able to build and deploy more of my hobbies, as well as collect more data to write more Medium articles about. Some of my next few planned articles include an analysis of the debt West Virginia University is currently facing financially as well as an exploratory data analysis of Nashville’s public safety reporting (and possibly an ML model for anticipating emergency events and allocating resource needs). These data science projects are large enough that they would not be possible without some sort of architecture for storing and querying the massive amount of related data.
What do you think? Does leaving the cloud and building a home lab sound like a project you would want to do? What would your hardware choice be?
If you’re curious about the hardware I used, check out my reviews at www.willkeefe.com
Some of my related recent Medium content:
Production Planning and Resource Management of Manufacturing Systems in Python
Efficient supply chains, production planning, and resource allocation management are more important than ever. Python…
Crime Location Analysis and Prediction Using Python and Machine Learning
Using Python, Folium, and ScyPy, models can be built to illustrate crime incidents, calculate the best locations for…

Written by Will Keefe
Engineer, python enthusiast, and fintech hobbyist.

Crime Location Analysis and Prediction Using Python and Machine Learning
Using Python, Folium, and ScyPy, models can be built to illustrate crime incidents, calculate the best locations for safety event resource…

How I Turned My Company’s Docs into a Searchable Database with OpenAI
And how you can do the same with your docs
Tabulating Subtotals Dynamically in Python Pandas Pivot Tables
One of the current disadvantages of the Pandas library’s built-in pivot functions is the lack of gathering subtotals dynamically for…

System Design Blueprint: The Ultimate Guide
Developing a robust, scalable, and efficient system can be daunting. However, understanding the key concepts and components can make the…
🐼Introducing PandasAI: The Generative AI Python Library 🐼
Pandas AI is an additional Python library that enhances Pandas, the widely-used data analysis and manipulation tool, by incorporating…